





Reducing AI context load using actions
When using an AI model, one of the things that you need to pay attention to is the number of tokens you send to the model. They literally cost you money, so you have to balance the amount of data you send to the model against how much of it is relevant to what you want it to do.
That is especially important when you are building generic agents, which may be assigned a bunch of different tasks. The classic example is the human resources assistant, which may be tasked with checking your vacation days balance or called upon to get the current number of overtime hours that an employee has worked this month.
Let’s assume that we want to provide the model with a bit of context. We want to give the model all the recent HR tickets by the current employee. These can range from onboarding tasks to filling out the yearly evaluation, etc.
That sounds like it can give the model a big hand in understanding the state of the employee and what they want. Of course, that assumes the user is going to ask a question related to those issues.
What if they ask about the date of the next bank holiday? If we just unconditionally fed all the data to the model preemptively, that would be:
- Quite confusing to the model, since it will have to sift through a lot of irrelevant data.
- Pretty expensive, since we’re going to send a lot of data (and pay for it) to the model, which then has to ignore it.
- Compounding effect as the user & the model keep the conversation going, with all this unneeded information weighing everything down.
A nice trick that can really help is to not expose the data directly, but rather provide it to the model as a set of actions it can invoke. In other words, when defining the agent, I don’t bother providing it with all the data it needs.
Rather, I provide the model a way to access the data. Here is what this looks like in RavenDB:
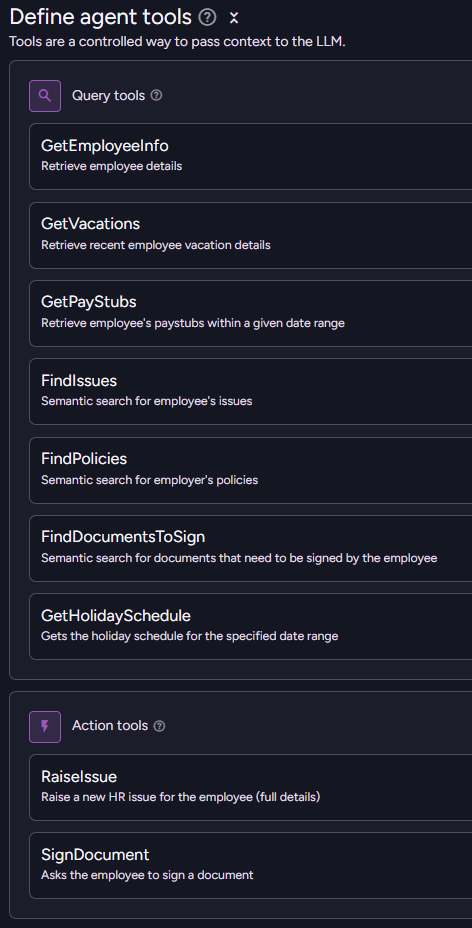
The agent is provided with a bunch of queries that it can call to find out various interesting details about the current employee. The end result is that the model will invoke those queries to get just the information it wants.
The overall number of tokens that we are going to consume will be greatly reduced, while the ability of the model to actually access relevant information is enhanced. We don’t need to go through stuff we don’t care about, after all.
This approach gives you a very focused model for the task at hand, and it is easy to extend the agent with additional information-retrieval capabilities.
Comments
Comment preview
Join the conversation...