Often, when introducing NHibernate, I need to integrate with existing database and infrastructures. Leaving aside the question of stored procedures (since I already expanded on that in length here), which are avialable on NHibernate 1.2, I want to focus on using SQL Functions here.
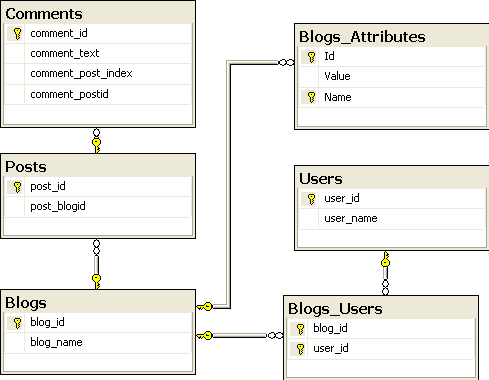
(One again, I'm back to the Blog -> Posts -> Comments model)
Now, there are four types of SQL Functions that you might want to use:
- Scalar functions that are a part of an entity.
A post's total spam score may be calculated using a SQL Function, and it is part of the properties of the object. - Scalar functions that are used for calculations, and should be called explicitly.
A blog's popularity score may be calculated using a SQL Function, but it is too expensive to calculate and not often needed.
Note: Only this requires NHibernate 1.2, all other features can be done using NHibernate 1.0.2 - Table valued functions (or stored procedure, for that matter, but that is a bit harder) that return entities:
A selection of posts with specific spam score it one example. - Scalar functions that you want to use as part of your HQL queries.
For instnace, you may want to use database (or user defined) functions as part of your HQL queries. Think lower(), dbo.postSpamScore(), etc.
Let us attack each of those in turn, shall we?
First, we have a scalar function that is a property of the entity, in this instance a post' spam score. The SQL Function is defined so:
CREATE FUNCTION GetPostSpamScore ( @postId INT )
RETURNS INT AS BEGIN
RETURN 42
END
Not very exciting, I know, but for our purposes, it is enough. Now, I need to define the following in the mapping file:
<
property name='SpamScore' formula='dbo.GetPostSpamScore( post_id )'/> The formula attribute is very powerful, you can even put SQL statements that will be executed as corelated sub queries (if you database supports it).
Q: Hi, what about aliasing? If I use this and join against another table that has a post_id (for instnace, the comments table), won't I get an error or unpredictable results?
A: No, NHibernate will automatically pre-pend the alias of the current entity table to anything that looks like a unqualified column access. If you need a column from another table, make sure to use the column with the qualifying name.
That is all you need to do to get the value from the function into your entities. In fact, you can now even perform HQL queries against this property, like this:
from Post p where p.SpamScore > 50
Second case, we want to get a scalar result from the database, and we are not interested in using ADO.Net directly to do so. Note that this is only possible with NHibernate 1.2, in NHibernate 1.0.2, you will need to use ADO.Net calls directly. Again, the SQL Function is very simple (for demonstration only, you can do anything you want in the SQL function, of course)
CREATE FUNCTION GetBlogTotalSpamScore ( @blogId INT )
RETURNS INT AS BEGIN
RETURN 42
END
Now, let us map this query so it would be easy to use...
<sql-query name='BlogSpamScore'>
<return-scalar column='SpamScore' type='System.Int32'/>
<![CDATA[
select dbo.GetBlogTotalSpamScore(:blog) as SpamScore
]]>
</sql-query>
And the code that uses this:
int spamScore = (int)session.GetNamedQuery("BlogSpamScore")
.SetEntity("blog", blog).UniqueResult();
A couple of points here. Notice that we are using the NHibernate notations for parameters in the query (:blog), and that we are passing an object to the query, not the identifier. I find this style of coding far more natural and OO than the equivalent ADO.Net code. For that matter, the equivalent ADO.Net code goes on for half a page or so... :-)
Third case, using a table valued function. Table valued function obviously cannot be used as a property of the entity. (To be exact, they can be used as a collection, but this is advanced functionality, and it is only avialable in NHibernate 1.2, so I'm not not going to cover it here). Fairly often, you want to use this for getting a collection of entities from the database using logic that reside in the database (for performance or historic reasons).
Here is my demo function:
ALTER FUNCTION GetAllPostsWithSpamScoreOfAtLeast( @minSpamScore int)
RETURNS TABLE AS RETURN
(
SELECT post_id, post_blogid FROM Posts
-- implement WHERE clause here
);
Now, let us map this for a set of entities:
<sql-query name='AllPostsWithSpamScoreOfAtLeast'>
<return class='NHibernate.Generics.Tests.Post, NHibernate.Generics.Tests'
alias='post'/>
<![CDATA[
SELECT post_id as {post.PostId}, post_blogid as {post.Blog}, 100 as {post.SpamScore}
FROM dbo.GetAllPostsWithSpamScoreOfAtLeast(:minSpamScore)
]]>
</sql-query>
Notice that I map all the colums to their respective properties (I could also use {post.*} if I wanted all of the columns without bother with specifying each and every one). And that I can pass parameters easily to the query.
Now, I can just query them like this:
IList list = session.GetNamedQuery("AllPostsWithSpamScoreOfAtLeast")
.SetInt32("minSpamScore", 5).List();
Against this is much more readable than the equivalent ADO.Net code, and I get full fledged objects back. If you want to do projections (show a post summary, etc. Using just part of the entity) you need to map the resulting projection as if it was an entity, NHibernate doesn't support SQL projections. (In practice, this is not an issue).
The last case is using user defined SQL Functions (or bulitin ones that NHibernate doesn't recognize by default) in your HQL queries. In order to do this, you need to either extend the dialect for your database, or dynamically add new functions to the dialect in the session factory (not really recommended).
Let us assume that you really want the ISOweek function. (See here for the implementation, if you really care). The function declaration is:
CREATE FUNCTION dbo.ISOweek (@DATE datetime) RETURNS INT
I would recommend extending the dialect for the database with the new function, like this:
public class MyDialect : MsSql2000Dialect
{
public MyDialect()
{
RegisterFunction("dbo.isoweek", new StandardSQLFunction(NHibernateUtil.Date));
}
}
A couple of things to note here. If this is a user defined function, you have to add the schema (in this case, dbo). The function name must be in lower case (HQL is case insenstive, so you can use whatever case you like in the queries, but you register the function with lower case). You then configure NHibernate to your MyDialect instead of your database dialect, and that is it. You can now issue HQL queries like this:
from Post p where dbo.ISOWeek(p.date) = 51
Note that you must still use the "dbo." in the HQL. Again, you can pass arguments naturally:
session.CreateQuery("from Post p where dbo.ISOweek( :date ) = 12")
.SetDateTime("date", DateTime.Now)
.List();
(Not that I can't think of a reason why you would want to excute the last two queries).
So, this is just about all you would ever want to know about SQL Functions, and if you kept reading up to now, you are really passionate about it.
Happy (N)Hibernating... :-)