





AI Agents Security: The on-behalf-of concept
AI Agents are all the rage now. The mandate has come: “You must have AI integrated into your systems ASAP.” What AI doesn’t matter that much, as long as you have it, right?
Today I want to talk about a pretty important aspect of applying AI and AI Agents in your systems, the security problem that is inherent to the issue. If you add an AI Agent into your system, you can bypass it using a “strongly worded letter to the editor”, basically. I wish I were kidding, but take a look at this guide (one of many) for examples.
There are many ways to mitigate this, including using smarter models (they are also more expensive), adding a model-in-the-middle that validates that the first model does the right thing (slower and more expensive), etc.
In this post, I want to talk about a fairly simple approach to avoid the problem in its entirety. Instead of trying to ensure that the model doesn’t do what you don’t want it to do, change the playing field entirely. Make it so it is simply unable to do that at all.
The key here is the observation that you cannot treat AI models as an integral part of your internal systems. They are simply not trustworthy enough to do so. You have to deal with them, but you don’t have to trust them. And that is an important caveat.
Consider the scenario of a defense attorney visiting a defendant in prison. The prison will allow the attorney to meet with the inmate, but it will not trust the attorney to be on their side. In other words, the prison will cooperate, but only in a limited manner.
What does this mean in practice? It means that the AI Agent should not be considered to be part of your system, even if it is something that you built. Instead, it is an external entity (untrusted) that has the same level of access as the user it represents.
For example, in an e-commerce setting, the agent has access to:
- The invoices for the current customer - the customer can already see that, naturally.
- The product catalog for the store - which the customer can also search.
Wait, isn’t that just the same as the website that we already give our users? What is the point of the agent in this case?
The idea is that the agent is able to access this data directly and consume it in its raw form. For example, you may allow it to get all invoices in a date range for a particular customer, or browse through the entire product catalog. Stuff that you’ll generally not make easily available to the user (they don’t make good UX for humans, after all).
In the product catalog example, you may expose the flag IsInInventory to the agent, but not the number of items that you have on hand. We are basically treating the agent as if it were the user, with the same privileges and visibility into your system as the user.
The agent is able to access the data directly, without having to browse through it like a user would, but that is all. For actions, it cannot directly modify anything, but must use your API to act (and thus go through your business rules, validation logic, audit trail, etc).
What is the point in using an agent if they are so limited? Consider the following interaction with the agent:
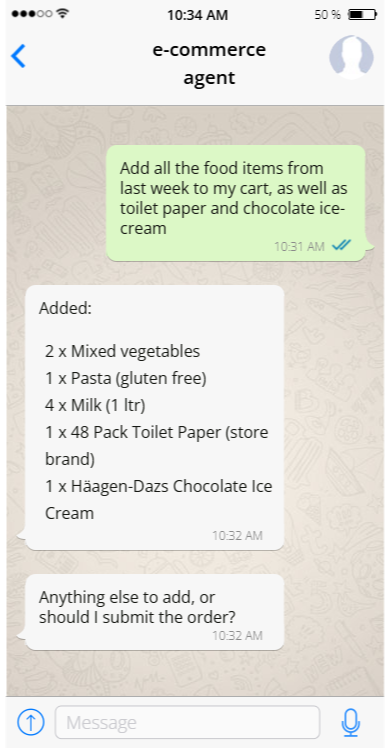
The model here has access to only the customer’s orders and the ability to add items to the cart. It is still able to do something that is quite meaningful for the customer, without needing any additional rights or visibility.
We should embrace the idea that the agents we build aren’t ours. They are acting on behalf of the users, and they should be treated as such. From a security standpoint, they are the user, after all.
The result of this shift in thinking is that the entire concept of trying to secure the agent from doing something it shouldn’t do is no longer applicable. The agent is acting on behalf of the user, after all, with the same rights and the same level of access & visibility. It is able to do things faster than the user, but that is about it.
If the user bypasses our prompt and convinces the agent that it should access the past orders for their next-door neighbor, it should have the same impact as changing the userId query string parameters in the URL. Not because the agent caught that misdirection, but simply because there is no way for the agent to access any information that the user doesn’t have access to.
Any mess the innovative prompting creates will land directly in the lap of the same user trying to be funny. In other words, the idea is to put the AI Agents on the other side of the security hatch.
Once you have done that, then suddenly a lot of your security concerns become invalid. There is no damage the agent can cause that the user cannot also cause on their own.
It’s simple, it’s effective, and it is the right way to design most agentic systems.
Comments
"There is no damage the agent can cause that the user cannot also cause on their own." I agree with this point, but we need to keep in mind the next level of exploits, and recognize that there is damage the agent can cause that the user would not cause on their own.
Case in point, GitHub Copilot executes commands in the user's terminal, and can thus be instructed to do anything the user could do... which becomes very problematic when it can also bypass human approval safeguards. Fortunately, that particular exploit has been patched. Unfortunately, we have absolutely no reason to trust that we're safe from any number of others.
Now in your example scenario, there is no terminal in play, but I'd say we still have trouble. Say a bad actor shares what appears to be a very helpful prompt, but they have performed similar exploits to hide extra instructions (e.g., buy e-gift cards and send them to the bad actor). Users throw these prompts into the system and of course they have permissions to make purchases on their own behalf. Or leave the bad actor out of it, and accept the reality that a non-deterministic lexical pattern engine may occassionally get a wild idea that the user wants to increase their automatic monthly contribution by 10x. Now we have to build another layer of guardrails around how far the agent can go, even on behalf of the user.
Henry,
You are correct, in that you still have security issues, but there is a whole different level of that. If I tell you to run:
eval(atob("YWxlcnQoJ3B3bmVkJyk="));on your end, and you do that... you are in the same situation.The key here is whether this is a user risk or a system risk. Because those need to be addressed very differently. An agent acting on-behalf-of the user is limited to what it can do. If the user misbehaves, that is a problem, but well scoped.
In the real world, consider the grandma getting a call saying from a supposed grandson: "I need to pay bail with gift cards, and it needs to be NOW". That is a problem, but it is not a problem for the bank.
On the other hand, if I were able to do the same thing to the bank's _teller_, it's a whole different ball game.
Ah, yes. Thanks, protecting the user versus protecting the system is a great distinction. For protecting the system, you're right, the harm an unwary user could do would remain limited in most scenarios. I do still worry about scenarios where the user is inside the system, where an agent acting on behalf of an unwary user would have broader scope. Say, a bank representative, HR department, developer just granted just-in-time access to prod, etc.
If you allow the agent to see any content generated by any other user, the agent can be hijacked. For example in an e-commerce setting letting the agent see reviews left by other customers or product descriptions from shady 3rd party marketers can cause your website to take unintended actions on the users behalf. This is similar to a xss attack.
If you maintain the state of the agent during a session or longer you have made it a persistent exploit vector. Limiting the agent to only see what the user can see seems insufficient. The key thing here is that anything the agent sees is a vector. Folks will naturally want their agents to see what they see, so I expect teams will open up these vectors. Things like: "List only the drills with no complaints about overheating" seem tailor made for LLMs. Listing them would be fine as a one shot, but then if you use the same session for other things like account management or modifying your cart you're wide open. While you may be able to defend system integrity, you're opening yourself up to legal liability.
Jason,
a) You are broadly correct - anything that you expose to the agent, you should be concerned about it affecting it. b) That is limited by what actions the agent can direct (which is distinct than take). c) We'll soon offer the ability to "nest" agents, to the point that you can have a split between "filter the no overheat" query from the "recommend the best value" agent.
Finally - at the end of the day, we are still dealing with a technology that has no actual control / data plane difference. In SQL - that is like not having parameters and hopsing that
replace("'", "''")would protect you.Going back to point (c) above - the agent isn't free to do whatever it wants, it must go through the available actions you provide to it. And then you have a chance to add validation, etc.
For example, if you are an under 18 customer, and try to buy alcohol. It isn't the LLM that is supposed to stop you, but the validation on the "AddToCart".
Comment preview