





Using AI for candidate ranking with RavenDB
Hiring the right people is notoriously difficult.I have been personally involved in hiring decisions for about two decades, and it is an unpleasant process. You deal with an utterly overwhelming influx of applications, often from candidates using the “spray and pray” approach of applying to all jobs.
At one point, I got the resume of a divorce lawyer in response to a job posting for a backend engineer role. I was curious enough to follow up on that, and no, that lawyer didn’t want to change careers. He was interested in being a divorce lawyer. What kind of clients would want their divorce handled by a database company, I refrained from asking.
Companies often resort to expensive external agencies to sift through countless candidates.
In the age of AI and LLMs, is that still the case? This post will demonstrate how to build an intelligent candidate screening process using RavenDB and modern AI, enabling you to efficiently accept applications, match them to appropriate job postings, and make an initial go/no-go decision for your recruitment pipeline.
We’ll start our process by defining a couple of open positions:
- Staff Engineer, Backend & DevOps
- Senior Frontend Engineer (React/TypeScript/SaaS)
Here is what this looks like at the database level:

Now, let’s create a couple of applicants for those positions. We have James & Michael, and they look like this:
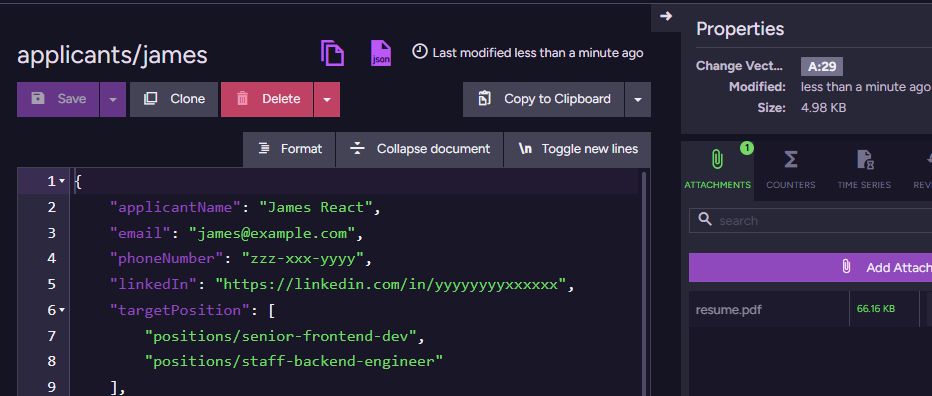
Note that we are not actually doing a lot here in terms of the data we ask the applicant to provide. We mostly gather the contact information and ask them to attach their resume. You can see the resume attachment in RavenDB Studio. In the above screenshot, it is in the right-hand Attachments pane of the document view.
Now we can use RavenDB’s new Gen AI attachments feature. I defined an OpenAI connection with gpt-4.1-mini and created a Gen AI task to read & understand the resume. I’m assuming that you’ve read my post about Gen AI in RavenDB, so I’ll skip going over the actual setup.
The key is that I’m applying the following context extraction script to the Applicants collection:
const resumePdf = loadAttachment("resume.pdf");
if(!resumePdf) return;
ai.genContext({name: this.applicantName})
.withPdf(resumePdf);When I test this script on James’s document, I get:
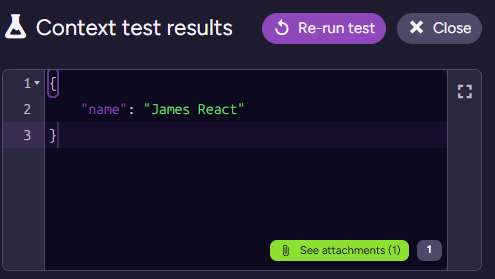
Note that we have the attachment in the bottom right - that will also be provided to the model. So we can now write the following prompt for the model:
You are an HR data parsing specialist. Your task is to analyze the provided CV/resume content (from the PDF)
and extract the candidate's professional profile into the provided JSON schema.
In the requiredTechnologies object, every value within the arrays (languages, frameworks_libraries, etc.) must be a single,
distinct technology or concept. Do not use slashes (/), commas, semicolons, or parentheses () to combine items within a single string. Separate combined concepts into individual strings (e.g., "Ruby/Rails" becomes "Ruby", "Rails").We also ask the model to respond with an object matching the following sample:
{
"location": "The primary location or if interested in remote option (e.g., Pasadena, CA or Remote)",
"summary": "A concise overview of the candidate's history and key focus areas (e.g., Lead development of data-driven SaaS applications focusing on React, TypeScript, and Usability).",
"coreResponsibilities": [
"A list of the primary duties and contributions in previous roles."
],
"requiredTechnologies": {
"languages": [
"Key programming and markup languages that the candidate has experience with."
],
"frameworks_libraries": [
"Essential UI, state management, testing, and styling libraries."
],
"tools_platforms": [
"Version control, cloud platforms, build tools, and project management systems."
],
"data_storage": [
"The database technologies the candidate is expected to work with."
]
}
}Testing this on James’s applicant document results in the following output:
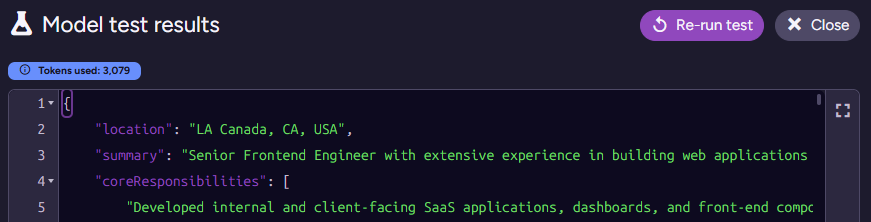
I actually had to check where the model got the “LA Canada” issue. That shows up in the real resume PDF, and it is a real place. I triple-checked, because I was sure this was a hallucination at first ☺️.
The last thing we need to do is actually deal with the model’s output. We use an update script to apply the model’s output to the document. In this case, it is as simple as just storing it in the source document:
this.resume = $output;And here is what the output looks like:
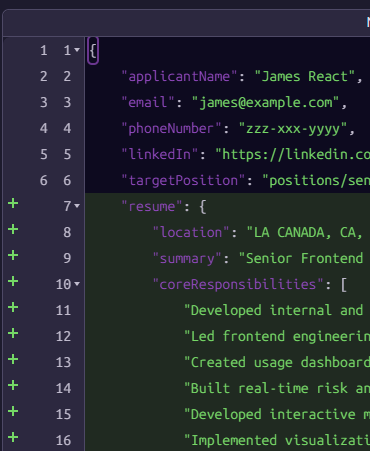
Reminder: Gen AI tasks in RavenDB use a three-stage approach:
- Context extraction script - gets data (and attachment) from the source document to provide to the model.
- Prompt & Schema - instructions for the model, telling it what it should do with the provided context and how it should format the output.
- Update script - takes the structured output from the model and applies it back to the source document.
In our case, this process starts with the applicant uploading their CV, and then we have the Read Resume task running. This parses the PDF and puts the result in the document, which is great, but it is only part of the process.
We now have the resume contents in a structured format, but we need to evaluate the candidate’s suitability for all the positions they applied for. We are going to do that using the model again, with a new Gen AI task.
We start by defining the following context extraction script:
// wait until the resume (parsed CV) has been added to the document
if (!this.resume) return;
for(const positionId of this.targetPosition) {
const position = load(positionId);
if(!position) continue;
ai.genContext({
position,
positionId,
resume: this.resume
})
}Note that this relies on the resume field that we created in the previous task. In other words, we set things up in such a way that we run this task after the Read Resume task, but without needing to put them in an explicit pipeline or manage their execution order.
Next, note that we output multiple contexts for the same document. Here is what this looks like for James, we have two separate contexts, one for each position James applied for:
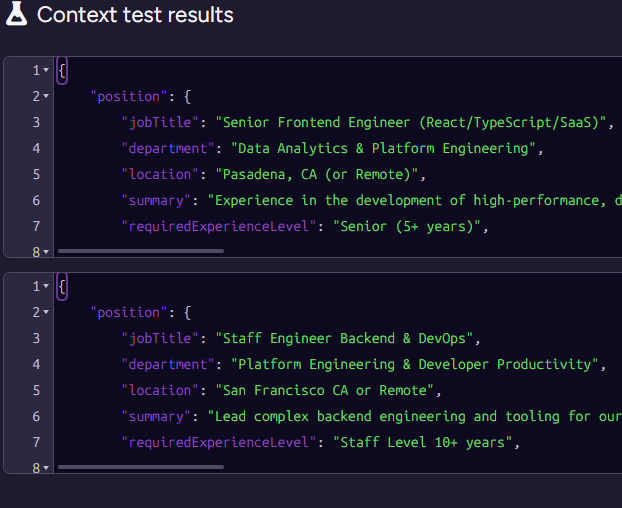
This is important because we want to process each position and resume independently. This avoids context leakage from one position to another. It also lets us process multiple positions for the same applicant concurrently.
Now, we need to tell the model what it is supposed to do:
You are a specialized HR Matching AI. Your task is to receive two structured JSON objects — one describing a Job Position and one
summarizing a Candidate Resume — and evaluate the suitability of the resume for the position.
Assess the overlap in jobTitle, summary, and coreResponsibilities. Does the candidate's career trajectory align with the role's needs (e.g., has matching experience required for a Senior Frontend role)?
Technical Match: Compare the technologies listed in the requiredTechnologies sections. Identify both direct matches (must-haves) and gaps (missing or weak areas). Consider substitutions such as js or ecmascript to javascript or node.js.
Evaluate if the candidate's experience level and domain expertise (e.g., SaaS, Data Analytics, Mapping Solutions) meet or exceed the requirements.And the output schema that we want to get from the model is:
{
"explanation": "Provide a detailed analysis here. Start by confirming the high-level match (e.g., 'The candidate is an excellent match because...'). Detail the strongest technical overlaps (e.g., React, TypeScript, Redux, experience with BI/SaaS). Note any minor mismatches or significant overqualifications (e.g., candidate's deep experience in older technologies like ASP.NET classic is not required but demonstrates full-stack versatility).", "isSuitable": false
}Here I want to stop for a moment and talk about what exactly we are doing here. We could ask the model just to judge whether an applicant is suitable for a position and save a bit on the number of tokens we spend. However, getting just a yes/no response from the model is not something I recommend.
There are two primary reasons why we want the explanation field as well. First, it serves as a good check on the model itself. The order of properties matters in the output schema. We first ask the model to explain itself, then to render the verdict. That means it is going to be more focused.
The other reason is a bit more delicate. You may be required to provide an explanation to the applicant if you reject them. I won’t necessarily put this exact justification in the rejection letter to the applicant, but it is something that is quite important to retain in case you need to provide it later.
Going back to the task itself, we have the following update script:
this.suitability = this.suitability || {};
this.suitability[$input.positionId] = $output;Here we are doing something quite interesting. We extracted the positionId at the start of this process, and we are using it to associate the output from the model with the specific position we are currently evaluating.
Note that we are actually evaluating multiple positions for the same applicant at the same time, and we need to execute this update script for each of them. So we need to ensure that we don’t overwrite previous work.
I’m not mentioning this in detail because I covered it in my previous Gen AI post, but it is important to note that we have two tasks sourced from the same document. RavenDB knows how to handle the data being modified by both tasks without triggering an infinite loop. It seems like a small thing, but it is the sort of thing that not having to worry about really simplifies the whole process.
With these two tasks, we have now set up a complete pipeline for the initial processing of applicants to open positions. As you can see here:
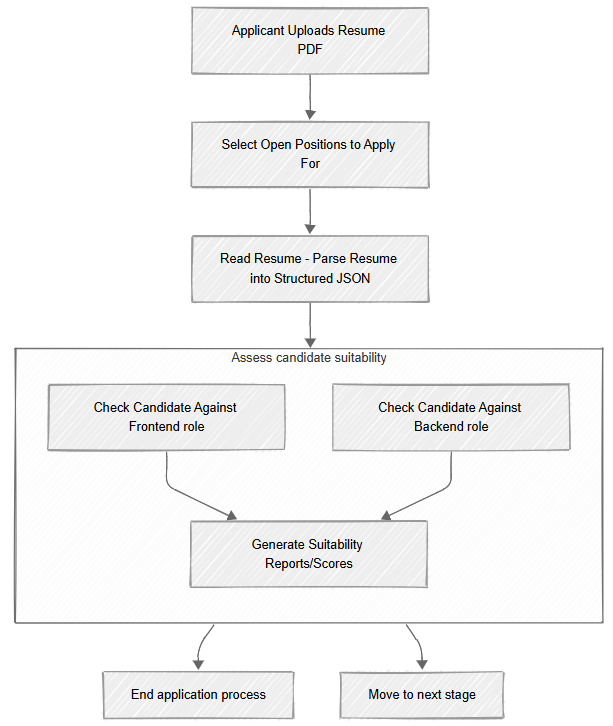
This sort of process allows you to integrate into your system stuff that, until recently, looked like science fiction. A pipeline like the one above is not something you could just build before, but now you can spend a few hours and have this capability ready to deploy.
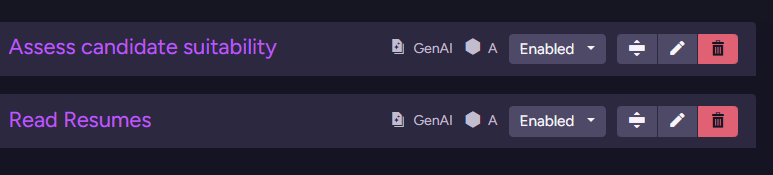
Here is what the tasks look like inside RavenDB:
And the final applicant document after all of them have run is:
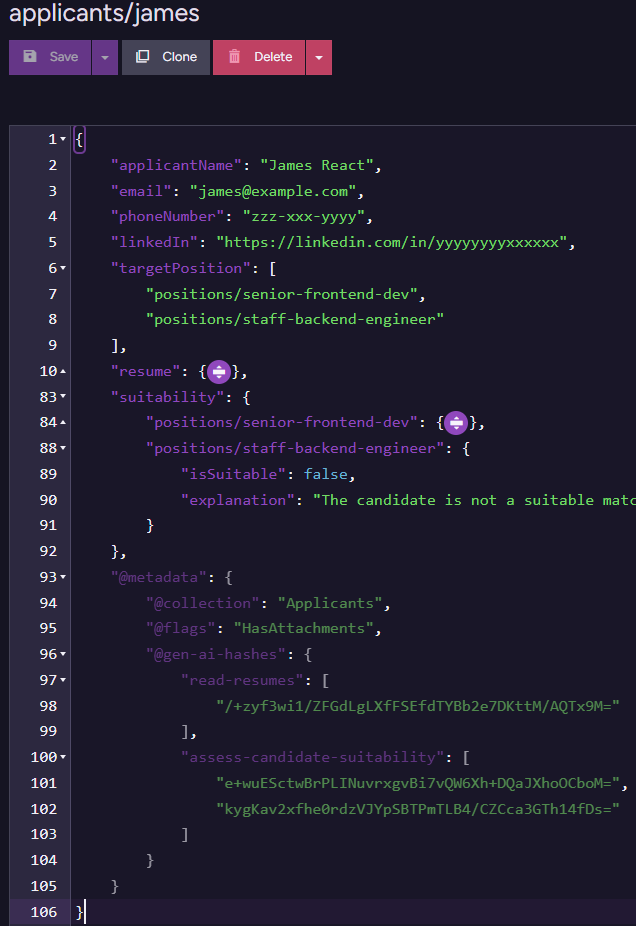
You can see the metadata for the two tasks (which we use to avoid going to the model again when we don’t have to), as well as the actual outputs of the model (resume, suitability fields).
A few more notes before we close this post. I chose to use two GenAI tasks here, one to read the resume and generate the structured output, and the second to actually evaluate the applicant’s suitability.
From a modeling perspective, it is easier to split this into distinct steps. You can ask the model to both read the resume and evaluate suitability in a single shot, but I find that it makes it harder to extend the system down the line.
Another reason you want to have different tasks for this is that you can use different models for each one. For example, reading the resume and extracting the structured output is something you can run on gpt-4.1-mini or gpt-5-nano, while evaluating applicant suitability can make use of a smarter model.
I’m really happy with the new RavenDB AI integration features. We got some early feedback that is really exciting, and I’m looking forward to seeing what you can do with them.
Comments
Comment preview