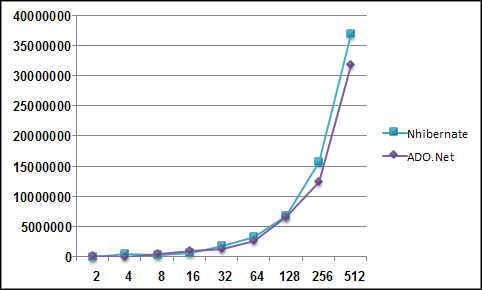
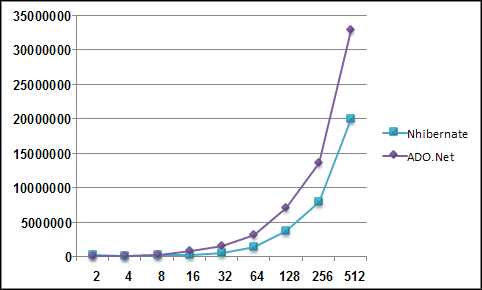
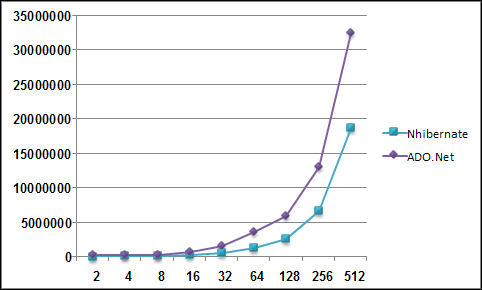
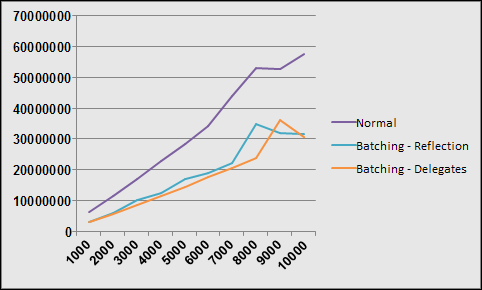
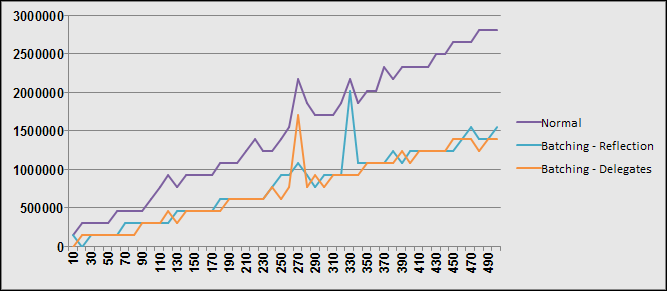
Note, this image was generate using Active Writer and represnt a domain model similar to a project I am currently working on. I spared you the prolifieration of DateTime in the model and merely put it in three or four places just to show what it was in general.
(continued below)
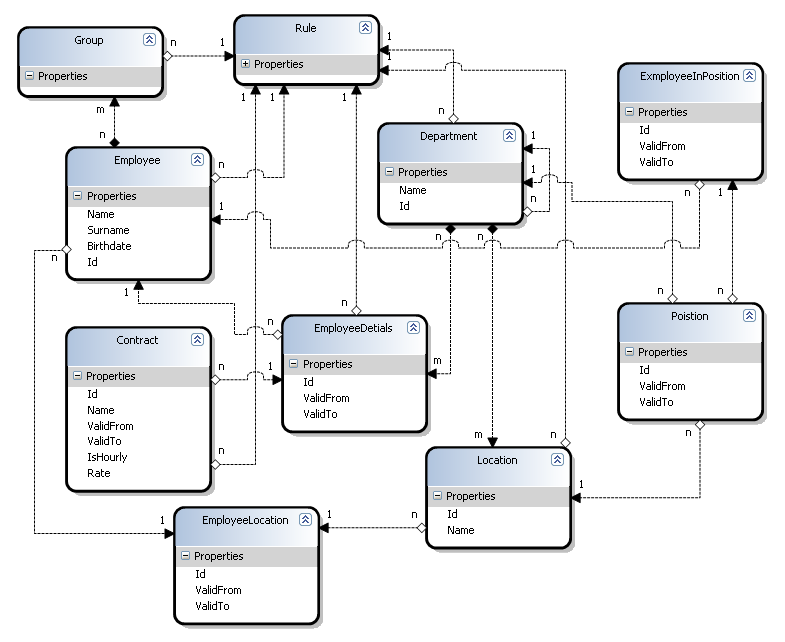
Now, this model is not showing unrelevant additonal entities (and entities attributes) but it is complete enough that you would understand the general theme of things. The requirement is finding all potential employees in the roganization for a specific vacant position.
Finding an employee consists of (with an implict "as of DD/MM/YYYY date" appended to each statement).
- Finding all the employees that are in the Position's Location at those date ranges.
- For each of those, verify that there isn't any rule broken if I position them there, discard those that break rules with high severity.
- For each of the remaining ones, display how many other employees in each of the employee's group are positioned in the same department, per each group the employee belongs to.
A typical output should be something like:
For poistion Manager in Mainframe Division:
- John Brane - Everyone: 9, MainFrame Guys - 3, Managers - 0
- Mariah G. - Everyone: 9, Managers - 0, Has MBAs - 2
Rules, as you can see in the diagram, are attached to pratcially everything, and they are inheritable to the N-th degree.
So, in order to verify that an employee positioned in a certain Position, I need to gather the following rules:
- Emloyee's current rules
- > All of the Groups the employee belongs to rules
- > All the location's rules
- > All the department (and all their hierarcies) rules
- Strip duplicate rules, using first come win approach. {duplicate rule is indicated by a rule type enum field}
That is per employee. And then I need actually run the rules, and a rule may need additional data (employee's other positions, past history, etc). Oh, and this really better be done on the fly. This is the issue that I am talking about here, which used to take positive infinity or more to run.
At the moment it is 01:17 AM here, so I'm going to leave the question open. How are you going to handle this case? Assuming that everything is mapped using NHibernate and you got full freedom to handle this any way you want. I'm going to see if anyone can come up with an interesting suggestion before I post how I handled this situation tomorrow.